
I did Advent of Code in the winter vacations!
Day 1: Secret Entrace#
Part A#
We have to first count the number of times the dial points to 0
| |
Part B#
and in part 2 we count the total number of times it passes through 0
| |
Day 2: Gift Shop#
Find the invalid IDs in a range of IDs
Part A#
Invalid IDs are those with with some sequence of digits repeated twice eg 6464, 123123 etc
| |
Here we split the number into 2 and compare the two halves
Part B#
Now an invalid ID is one that is repeated at least twice, so 111 is also invalid now though it wouldn’t have been earlier
| |
Now instead of splitting it in 2, we create a splitter function that checks if 1 digit is repeated throughout, then 2 digits, and so on (in the reverse order actually but ok)
Day 3: Lobby#
Given long strings of “battery banks” each with a single digit “joltage”, find a way to get the required joltage.
Part A#
Just had to get the largest two digit subsequence
811111111111119 gives 89
| |
Find the maximum digit before the last one, then find the next maximum digit after that.
Part B#
Apparently more power is needed and now you need to select the largest 12 digit subsequence
| |
We apply the same idea but as earlier create a helper function and check all but the last 11 digits, then all but the 10 and so on
Day 4: Printing Department#
This is where things start getting a bit more interesting. Given a grid of “paper rolls” we need to check if they are accessible by a forklist by counting the number of neighbours. An example graph
..@@.@@@@.
@@@.@.@.@@
@@@@@.@.@@
@.@@@@..@.
@@.@@@@.@@
.@@@@@@@.@
.@.@.@.@@@
@.@@@.@@@@
.@@@@@@@@.
@.@.@@@.@.Part A#
First we tell them how many rolls are accessibile. A roll is accessible if it fewer than 4 neighbours
| |
Since we only need neighbours, there is no need to work on the whole graph, I maintain a sliding window q of 3 rows. Each cell in q stores the number of neighbours of that cell
update_queue() is a function that takes a line of the input graph, and based on wherever there is a paper roll, increments the number of neighbours for each position adjacent to it
| |
Then check_row() can simply look at all the paper roll cells and count the ones with value less than 4.
Part B#
Now we need to do the same again, but until there are no more accessible paper rolls. i.e. if a paper roll is accessible, we remove it, and in the process free up more paper rolls. This was a slight challenge since I was using a sliding window instead of keeping the entire grid, but it ended up not mattering much
| |
We can now store a per-iteration result and a global count, and we iterate while we still have accessible rolls, i.e. result != 0. Also every time we check a row, we remove the accessible rolls from the grid to free up more rows in the next iteration
| |
Day 5: Cafetaria#
Given intervals of fresh ids, and a list of ids
Part A#
Find the number of IDs that fall in the fresh intervals
| |
And that’s it lol
Part B#
This is slightly more challenging, but ends up becoming easy to implement. Now we are asked to find the total number of fresh ids, which sounds easy, but there ranges are allowed to overlap in the input, and you must consider those
This is where python’s intervaltree module comes in
An interval tree is a data structure that stores intervals, and is optimised for the question, “which of these intervals overlap with a given interval”. This makes merging intervals rather easy here giving us some very short code
| |
I add the 0.1 on line 5 because the python implementation treats intervals as [x, y) whereas we are told they are inclusive of both i.e. [x, y].
Here are some links about the interval tree
Day 6: Trash Compactor#
Time to solve math homework
Part A#
123
45
6
* translates to 123 * 45 * 6 = 33210
Given a long list we have to calculate the sum of all answers
| |
I first read the operations line (the last line) and based on those init a results array. Addition problems init the answer to 0, multiplication ones to 1.
Then as we read the numbers line by line we can keep performing the required operation and storing the results! That was fairly straightforward
Part B#
Time to make me regret my life decisions. AoC involves so much weird parsing T-T
123
45
6
*is now interpreted as 356 * 24 * 1 = 8544
| |
Now I have to store the input as a grid of characters, parse the grid column by column and proceed. If no number is found on that column, I know my problem has ended and I move on to the next problem
Day 7: Laboratories#
.......S.......
...............
.......^.......
...............
......^.^......
...............
.....^.^.^.....
...............
....^.^...^....
...............
...^.^...^.^...
...............
..^...^.....^..
...............
.^.^.^.^.^...^.
...............Part A#
Count the number of times the beam splits
| |
Easy enough to simulate, basically every time the an active beam encounters ^ you increment
Part B#
Now you need to calculate every possible path a single beam could go through, given at every ^ it goes either left or right.
Due to the scale of the problem we use DP
S
00100
^
01010
^ ^
10201 Consider the above example,
- We start at S, and the value of 1 at S represents the paths that can pass through it.
- Once it is split, there is no path on that exact cell, but one is created on both sides of it
- The next time both those paths split, if the beam passes through the cell between the two
^, it could have come from either the left or the right, so two paths pass through that cell
We can represent this with a dp array where
if grid[j] == '^':
dp[j-1] += dp[j]
dp[j+1] += dp[j]
dp[j] = 0And finally the sum of all cells in dp[] gives us the total number of paths possible
| |
Day 8: Playground#
This was one of the wildest ones. I was using such random random algorithms from cp-algorithms. I even added a custom hash function for a 3d point 😭
You’re given a long list of (x, y, z) points
It’s honestly not too bad in terms of execution, but the code is horrible and I truly do not understand what I wrote, this will be a journey we undergo together.
You must connect the 1000 closest points, and see what circuits they make. A string of connected points forms a circuit
Let’s first handle the closest points part
Nearest Points#
Everything mentioned here can be found in the helpful cp-algorithms page
We implement a linear time randomised algorithm to populate a priority queue with the 1000 closest points
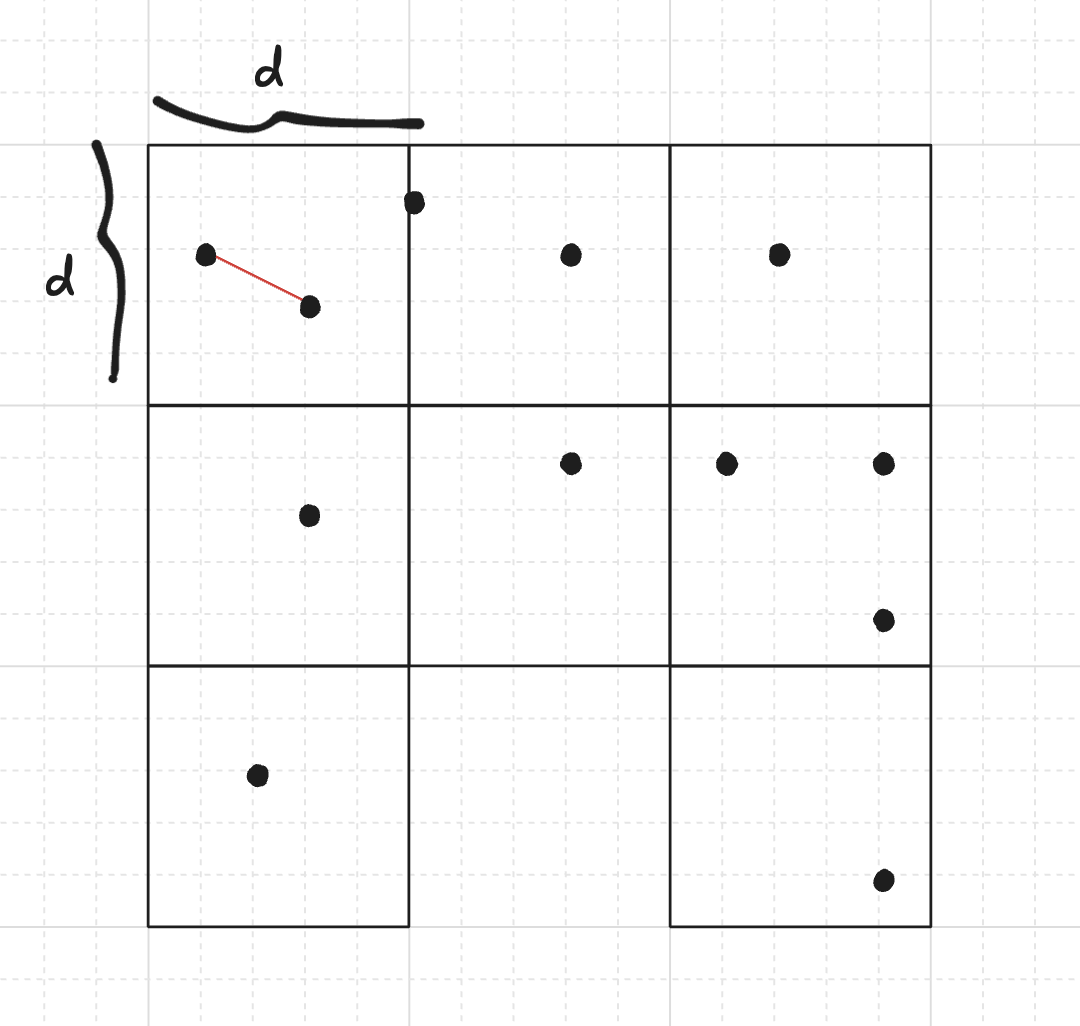
essentially we break up the 3D grid into smaller cubes, and then look in those cubes for nearest points.
First we select the dimension of each block d then iterate over points in the same block, and finally over those in adjacent blocks
Here’s my C++ implementation. Note that sometimes my hash function didn’t manage to unique hash every point so in my constructor I force it to repeat until I’m sure my hash function did it’s work and I have enough pairs in my priority queue
| |
Disjoint Circuits#
Once we have our required pairs, we need to start making connections and count the number of disjoint circuits formed. We can use the very cute Union-Find data structure for this! (aka Disjoint Set)
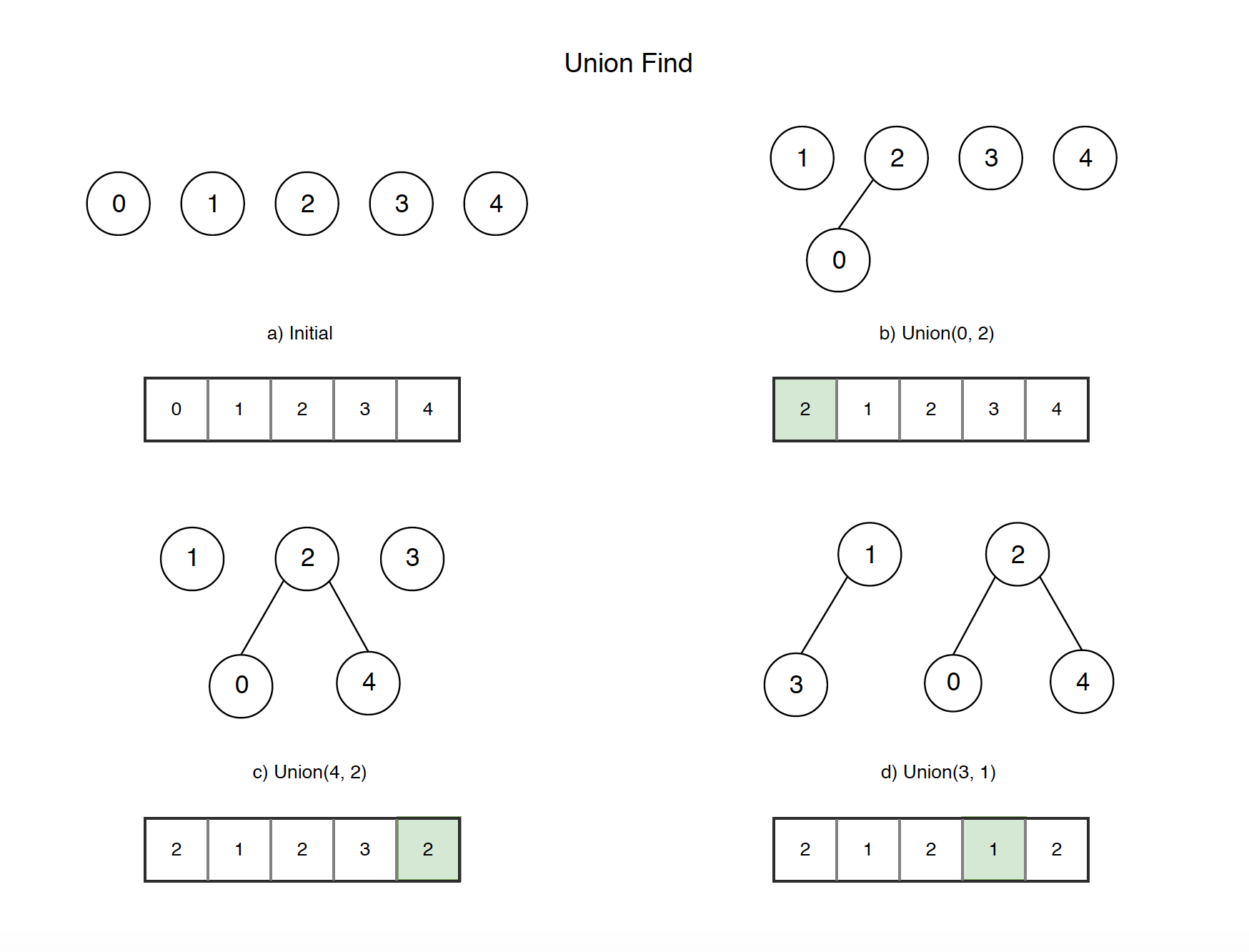
| |
Here’s my simple implementation weighting by size, I add an ans() function to return the size of the 3 largest disjoint circuits
With these two setup we can finally solve our Part A
Part A#
| |
Simply pop a pair from the priority_queue and put it into union find.
You may notice I have to handle duplicate pairs. Remember in my closest points implementation, every time I compare two points I add them to the priority queue? Well we initially sample 1000 pairs to approximate a minimum distance d before we finally iterate over every candidate pair in the resultant grid. This led to duplicate pairs being formed in the priority queue that I have to handle here. Welp, sorry about that.
Part B#
Now we have to continue until we form a single circuit. It’s a simple extension to Part A, we just keep going until Union Find does not have any disjoint sets, which is a simple enough check
int count_sets() const {
int sum{0};
for (size_t i = 0; i < parent.size(); i++) {
if (parent[i] == static_cast<int>(i))
sum++;
}
return sum;
} | |
I no longer have to handle duplicates since I don’t care about how times I union the same pair of points! Union-Find handles that for me, so cute!
Wow, that was some journey. Apparently I could have just sorted the distance between every possible pair, that wouldn’t have been too slow
Day 9: Movie Theatre#
If you thought Day 8 was bad, let me please please please make you more disappointed with me. At least Day 8 was somewhat performant and well intentioned. Look at my runtime for Part B 😭
❯ time python day9_b.py
1351617690
________________________________________________________
Executed in 25.15 secs fish external
usr time 25.04 secs 0.14 millis 25.04 secs
sys time 0.01 secs 1.01 millis 0.01 secsI truly apologise :(
Given a grid like below
..............
.......#...#..
..............
..#....#......
..............
..#......#....
..............
.........#.#..
..............We have to work with the rectangles formed by the points on the grid
Part A#
Just says to find the largest possible rectangle of any two points, this is a simple brute force
| |
Part B#
Now we come to the interesting problem. The list of points given to us, in the order given, always forms a polygon
97498,50350
97498,51566
97867,51566input looks something like this, notice the alternating x and y coordinates.
The challenge is now to find the largest rectangle
- between two points
- that fits inside the given polygon
So we do our earlier thing, but now check if it’s inside the polygon??? When I was going through the interval trees for day 5 I saw somewhere that you could store polygons as sets of intervals, an x-intervaltree for the horizontal edges, and y-intervaltree for vertical edges
So that’s what I did. Now to check if a rectangle formed by our two points lies inside the polygon, we need to ensure two things
- No edge of the rectangle intersects any edge of the polygon (i.e. its wholly inside or outside)
- The center of the rectangle is inside the polygon
The first is where our interval tree shines (this is sarcasm, literally all the execution time goes in that check)
def intersecting_edges(a, b):
x1, y1 = a
x2, y2 = b
x_min, x_max = min(x1, x2), max(x1, x2)
y_min, y_max = min(y1, y2), max(y1, y2)
for iv in xtree.overlap(x_min, x_max):
if y_min < iv.data < y_max:
return True
for iv in ytree.overlap(y_min, y_max):
if x_min < iv.data < x_max:
return True
return FalseTo check if the rectangle created by two points a and b intersects any other edge we use the intervaltree.overlap() method which returns the edges that overlap the given interval, and we check the remaining coordinate of that edge if it lies inside our rectangle. If it does, clearly it intersects it.
def ray_casting(a, b):
mid = [(a[0] + b[0]) // 2, (a[1] + b[1]) // 2]
h_edges = xtree.at(mid[0])
above = 0
for e in h_edges:
if e.data > mid[1]:
above += 1
left = 0
v_edges = ytree.at(mid[1])
for e in v_edges:
if e.data < mid[0]:
left += 1
return above % 2 != 0 or left % 2 != 0Once we get our rectangle, we can throw a vertical edge through its centroid. If that edge passes through an odd number of polygon edges, it is inside it, otherwise it must be outside the polygon. Having a rectangle that’s just a line (same x/y coordinate) adds some difficulty which is why I check against both horizontal edges and vertical edges (I should probably just ignore the 1D rectangles though)
| |
Can you see the slight optimisation? My most expensive function is definitely the .overlap() method in the intersecting_edges check, so if I only compute that for candidate rectangles with area greater than current max I can save some time.
a = area(points[i], points[j])
if a > max_area:
if not intersecting_edges(points[i], points[j]) and ray_casting(points[i], points[j]):
max_area = max(max_area, a)This saves me about 6-7 seconds (😉)
Here’s what the polygon looks like btw

Eventually I’ll do something better, jverkamp day9 looks interesting
Day 10: Factory#
This was a really interesting one, and originally stumped for a long, long time. Eventually I gave up and took a hint from @jverkamp’s writeup
The premise is as follows
[.##.] (3) (1,3) (2) (2,3) (0,2) (0,1) {3,5,4,7}Your input line has 3 parts, the expected light diagram, the buttons, and the required joltages
Part A#
Each button toggles the light specified and we have to reach the final light diagram from all off LEDs in minimal button presses.
My initial approaches looked like trying to find a linear combination of buttons whose values XORed to the required configuration, but I couldn’t make it minimal and gave up.
A long time later, I took a hint and saw the word “BFS”
We can do a breadth first search over the possible light configurations, applying the button presses at each iteration, and the first configuration to match is guaranteed to have minimal button presses!
| |
Part B#
Part B adds a lot more constraints, and now joltage plays a part too. Each time a button is pressed, the joltage for those LEDs goes up, and now we must find the minimal button presses that also solve our joltage requirements
This adds a lot of constraints, and looking at the hint again, I decided to use z3
We add z3 variables for the number of times each button is pressed, and the buttons themselves. The XOR constraints ensure the final light configuration is reached, and the number of presses ensure that joltage requirements are reached
| |
Day 11: Reactor#
This was a pretty straightforward day, simple graph algorithms
aaa: you hhh
you: bbb ccc
bbb: ddd eee
ccc: ddd eee fff
ddd: ggg
eee: out
fff: out
ggg: out
hhh: ccc fff iii
iii: outGiven adjacency lists like do stuff
Part A#
Count the number of paths from you -> out. Apply straightforward BFS starting from you and increment by 1 everytime you reach out?
| |
Part B#
Now we need to ensure every path to out goes through the nodes dac and fft.
What I did here is attach a state tuple to the BFS queue that tracks whether those nodes were visited or not, and I only increment my counter if they were both visited. This time however we start from the node svr which has a LOT more paths to out, and can no longer perform standard BFS. We need memoisation.
So we create a memo and make our implementation recursive to accomodate the memo
| |
And inside of main
map<tuple<string, bool, bool>, long long> memo{};
long long num_paths{count_paths(make_tuple("svr", false, false), graph, memo)};Day 12: Christmas Tree Farm#
There was only one part to this yay. Also my solution was such a fluke I didn’t even try to accurately answer the problem
Basically the problem is we’re given a lot of shapes, and have to fit the required shapes into regions of size A x B
Shapes look like
4:
###
#..
###
5:
###
.#.
###etc, and a region would look like
4x4: 0 0 0 0 2 0which says we have two instances of shape 4 into a region of size 4x4.
Part A#
We have to count the number of regions that can fit the shapes they specify. The absolute most rudimentary to check this would be a simple area check. If the total shapes area is <= the area of the region, it might fit. So let’s count that first
for (const region_t ®ion : regions) {
long long area = region.first.first * region.first.second;
long long required_area{0};
for (size_t i = 0; i < region.second.size(); i++) {
if (region.second[i]) {
required_area += region.second[i] * shape_area(shapes[i]);
}
}
if (required_area <= area) {
answer++;
}
}And thankfully for us this is the required answer. Otherwise we were screwed, I can’t think of anything, nor did I find any other solution, besides just backtracking and checking every combination of shapes on that grid.
That was an experience, and a rather fun one.
Reply by Email