We looked at what critical sections are, the general structure of a process with a critical section is
do { /* * Entry Section * - Request Permission to enter */ // critical section /* * Exit Section * - Housekeeping to let other processes enter */ // remainder section} while (true);
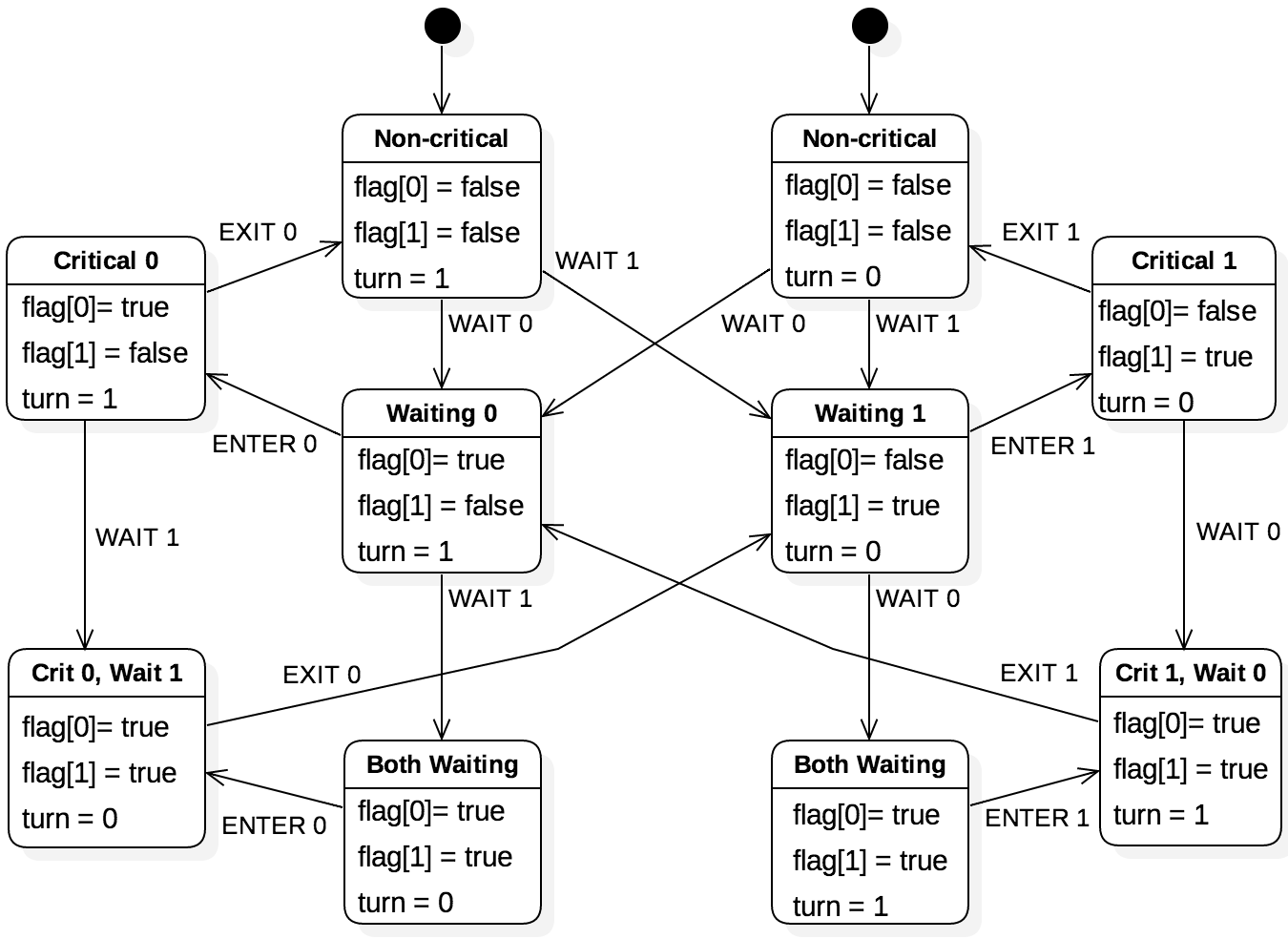
The Critical Section Problem
Given a system of n processes, where each process has a critical section, and no two processes can execute in their critical sections at the same time.
Any solution to this problem must satisfy certain conditions
Mutual Exclusion
only one process can execute in its critical section
Progress:
if No process is executing in its critical section
and, Some processes wish to enter their critical sections
then a decision must be made as to who enters.
The decision can not be postponed indefinitely
Bounded Waiting:
After a process has requested permission to enter its critical section
It must be allowed to enter after a finite amount of other processes
Software Solutions
Certain software solutions were explored before realising that hardware support would be crucial. The primary problems with software solutions are
the unavoidable busy wait
compiler optimisations can rearrange your code in undesirable ways
if different threads are run on different cores that do not guarantee cache coherency, t he threads may be using different memory values
software solutions also suffer from their lack of abstraction
Dekker’s algorithm was the first provably correct solution to the critical problem. It requires both an array of boolean values, and an integer variable.
bool flag[2]; // represents intent to enter critical sectionint turn = 0; // represents current process in critical section
Mutual Exclusion: Consider the two cases, a process is in its CS and the other one wants to enter, and both processes try to enter at the same time
Case 1: suppose j is in its CS, then i specifically waits until j sets flag[j] = 0 which it only does after it exits its CS
Case 2: suppose j and i both set their intent to enter their CS, however at any moment the turn variable can only point to one of the processes and thus only one of them can enter their CS. It alternates between both processes and is only modified at the end of the CS.
Progress: Consider the two cases, a process tries to enter with no competition, and two processes try to enter simultaneously
Case 1: the flag of the other process is not set and thus it can enter unimpeded
Case 2: if one of the processes is stuck in its while loop, the turn variable forces one of the processes to lower its flag, allowing the other process to enter its critical section
Bounded Wait:
A process that has just left its CS will be blocked from entering again because it has set turn to the other process
Peterson’s Solution
int turn = 0; // whose turn currentlybool flag[2]; // is the process ready to enter its CS
do { flag[i] = true; turn = j; // give j its turn first while(flag[j] && turn == j); /* critical section */ flag[i] = false; /* remainder section */} while (true);
Similar to the above analysis we can see Mutual Exlusion and Progress are preserved. The slight change occurs with Bounded Wait where the process i always allows j to run before it and vice versa. This creates a bound of at most one process that enters before i is allowed to enter its CS
Premature Process Exits
suppose process i has just set turn = j, but j exited on the last iteration. There’s no one to give turn back to i now. Can i still continue running??
It’s important to note that a good solution the problem does allow i to continue running. This is necessary for “Progress” to be satisfied and indeed is the purpose of the flag[2] variable, because j is no longer running it can’t raise its flag and thus i knows not to wait for it
do { flag[i] = true; turn = j; if (flag[j]) { while(turn == j); } /* critical section */ flag[i] = false; /* remainder section */} while (true);
Can you spot the mistake in this variation of Peterson’s solution? Look for how it violates “Progress” by only relying on turn to exit its wait instead of flag too (line4)
Compiler Optimisations
An issue with software solutions is the possibility of compiler optimisations changing the order of statements.
Digressing for a moment, you may wonder why we give the turn to the other process in the entry section of Peterson’s solution. It may feel more natural to first complete the critical section, then handoff in the exit section
For example:
#include <pthread.h>#include <stdio.h>#include <stdlib.h>#include <time.h>#include <unistd.h>static volatile int flag[2];static volatile int turn = 0;static volatile int counter = 0;void *peter(void *x) { int id = *(int *)x; char id_ = 'A' + id; int other = 1 - id; for (;;) { // entry section flag[id] = 1; while (flag[other] && turn == other) { } // critical section printf("%c: begin %d\n", id_, counter); usleep(500 + (rand() % 1000)); counter++; printf("%c: end %d\n", id_, counter); // exit section flag[id] = 0; turn = other; // remainder section if (counter >= 10) { break; } } return NULL;}int main() { flag[0] = 0; flag[1] = 0; srand(time(NULL)); int a = 0; int b = 1; pthread_t i, j; pthread_create(&j, NULL, peter, &b); pthread_create(&i, NULL, peter, &a); pthread_join(i, NULL); pthread_join(j, NULL); return 0;}
This example violates “Mutual Exclusion” in a subtle way
Here’s the output:
❯ build peterson.c threadCompilation successful: threadB: begin 0A: begin 0A: end 1B: end 2A: begin 2A: end 3B: begin 3B: end 4...
Thread B ran before A and since flag[A] was not set, it was allowed to enter it’s critical section.
The next moment when A ran it was A‘s turn and it was also allowed to enter it’s critical section, violating “Mutual Exclusion”
Coming back to compiler optimisations, we establish that we need to set intent to enter the critical section before we hand over the turn. i.e.
flag[i] = true; // always beforeturn = j;
However compilers, in their optimisations, can change the order of seemingly “independent” statements, and may change your machine code to represent
turn = j; // beforeflag[i] = true;
which as we saw above is a violation of mutual exclusion since i may have the turn but not the intent, and j may have the intent but not the turn, letting them both enter their critical sections
Hardware Solutions
We can rephrase our solutions to the critical section problems with the concept of Locks, where we first acquire a lock, enter our critical section, then release the lock
fairness: threads trying to acquire locks should not starve
low cost and performance
Interrupts
On single processor systems, the primary cause for the critical section problem is the timer interrupt that preempts processes, so a potential solution would be too simply disable interrupts in the critical section
you may have noticed the example above won’t actually work. On my computer it exits during runtime with a SIGSEGV. It’s because enabling/disabling hardware interrupts is a very privileged operation. You also can’t trust threads with such power
This approach is also specifically limited to single processor systems. Multi Processor systems need to be able to switch between processes and can not let any process run unattended. Even if a single thread disables its interrupts, the other threads can run on the other cores
We also don’t want to ignore interrupts, they usually interrupt us for a reason
Test and Set
Moving on from our interrupt adventures we can set a more intuitive flag telling other threads whether the mutex is locked or not.
typedef struct __lock_t { int flag; } lock_t;void init(lock_t *mutex) { mutex->flag = 0; }void lock(lock_t *mutex) { while(mutex->flag == 1); // TEST the flag mutex->flag = 1; // SET the flag}void unlock(lock_t *mutex) { mutex->flag = 0; }
However once again we must be very careful, consider two threads trying to acquire the lock at the same time. If lock is interrupted after the while, both threads will manage to acquire the lock, therefore we must also ensure that lock is not interrupted
thread 1
thread 2
while(flag == 1);
interrupt: switch to thread 2
while(flag == 1);
flag = 1;
interrupt: switch to thread 1
flag = 1;
When system designers faced this need for atomicity, they created the Test and Set hardware instruction, guaranteed to be atomic
int TestAndSet(int* lock, int new) { int old = *lock; // fetch old value for TESTING *lock = new; // SET new value return old;}
On x86 TestAndSet is implemented in the xchg instruction2
So we fix our lock/unlock interface with this new instruction
The exit section implements a bounded wait, because it always checks if another thread is waiting and tries to give it the lock first before freeing it. We have a finite bound of upto n−1 that each thread must wait before getting its turn
Load-Linked and Store-Conditional
Store-Conditional just ensures that it is the first store to an address loaded by Load-Linked. If it isn’t it fails with an error
With these load/stores we can go back to our original implementation of the lock() function
int StoreConditional(int *ptr, int val) { if (/* no update to ptr since LL to this addr */) { *ptr = val; return 1; // first store! } else { return 0; // not first store :( }}
void lock(lock_t *mutex) { for (;;) { while(LoadLinked(&mutex->flag) == 1); if (StoreConditional(&mutex->flag, 1) == 1) { return; } // else try again }}
MIPS offers these lmao
Fetch and Add
Another offered primitive is FetchAndAdd
int FetchAndAdd(int *ptr) { int old = *ptr; *ptr = old + 1; return old;}
So far of all our lock implementations, this is the only one that ensures progress for all requesting threads. Because unlock() will always give the turn to the next thread instead of potentially letting lock() claim it again
Busy Waits and Spin Locks
So far all the waits we have seen have been busy waits where the thread keeps spinning to check if the lock has been freed yet or not. This is a waste of time quanta, and we would prefer moving a waiting thread to some sort of idle queue instead, moving it to the ready queue when the lock is finally available. We can update our lock_t to be aware of this
typedef struct __lock_t { int flag; int guard; queue_t* q;} lock_t;void lock_init(lock_t *lock) { lock->flag = 0; lock->guard = 0; queue_init(lock->q);}void lock(lock_t* m) { // acquire guard lock by spinning while(TestAndSet(&m->guard, 1) == 1); if (m->flag == 0) { m->flag = 1; // acquire lock m->guard = 0; } else { queue_add(m->q, gettid()); m->guard = 0; // POTENTIAL RACE CONDITION HERE pause(); // put thread to sleep }}void unlock(lock_t* m) { // acquire guard lock by spinning while(TestAndSet(&m->guard, 1) == 1); if (queue_empty(m->q)) { // let go of lock // no one wants it m->flag = 0; } else { // transfer lock to waiting thread wakeup(queue_remove(m->q)); } m->guard = 0;}
Priority Inversion
The problem with busy waiting goes further than just a matter of performance, spinwaiting can sometimes lead to deadly situations
The Problem With Spin Waiting
consider a computer with two processes H and L, with high and low priority respectively
now consider L is in its critical section, and H is requesting to enter it’s own critical section.
H is going to be scheduled before L always but all it does is wait for L to finish, leading to a locked situation where no one can do anything.
The solution to this is Priority Inheritance where if a H waits for an L, the L inherits the priority of H to run to completition faster.
Priority Inversion is an intergalactic problem that occurred even on Mars in 19973, when their data collection process would constantly be preempted by other medium priority tasks, causing a delay that would force Pathfinder to keep resetting itself